DICOM XAという深遠にして難解なる世界への手がかり
DICOM-XAという動画フォーマットは、医療画像診断分野において1997年頃より全世界の医療現場・研究において用いられてきたものです。このDICOMフォーマットの制定により、全世界で統一されたフォーマットで画像情報を正確に伝達・保存が可能となったのです。しかしながら、その動画フォーマットであるDICOM-XAというものは、難解なデータ構造を持っています。
齋藤 滋は、2010年頃に、C/C++プログラミングの勉強のために自身でその動画再生プログラムを作成することを決意しました。しかし、それは困難と苦痛に満ちた試みでした。DICOM-XAは静止画のフォーマットである JPEGに基づいています。そして JPEGというフォーマットの根源にあるのは、ハフマン符号化というデータ欠損の無い圧縮です。なぜ、DICOM-XAが難解であるか? と問われれば、その多くは、肝腎のHuffmannフォーマットに関する明確な記述が JPEG仕様書にしか存在しないからであり、その JPEG独特の符号化をプログラミング言語で記載したものの解説は世の中にほとんど存在しないからでした。このような荒波の中、DICOM-XAの解読プログラム(=動画再生プログラム)を自分自身でフル・スクラッチ (=ブックボックス・プログラムやライブラリなどを利用せず、ゼロからコードを書くこと)で書くことに私は挑戦しました。ここに、この齋藤 滋自身が歩んできた困難に満ちた長い戦いの記録を残します。
ビット列解読における重要な前提
2013年8月5日
DICOMにしろ、JPEGにしろ、あるいは世の中の電子的な情報伝達においては、基本的にonかoffしか信号としてはありません。つまり、1か0なのです。何故、1, 2, 3, 4,・・・, 9ではないのでしょうか? 疑問に思わないですか?
その理由は、1 or 0、白か黒、あるいは On or Offというのは違いが一番明確です。しかし、1と2の違いは、3と4の違いでもあり、差という見方をすれば、1も3も見分けがつかないことになります。自然界の中で情報を伝える時には、1 or 0、あるいは昼か夜のように二者択一の方が周囲の雑音の影響を受けにくくなることは容易に想像できますよね。これが、二進法が電子的情報伝達に用いられる理由なのです。
しかし 0と 1 (これを二者択一ということで、BIT ビットと称します)の数列は人間には理解しにくいものです。そこで、便宜的に、0 or 1を8個まとめて(これを 8 bits = 1 BYTEバイト)表記することが行われます。8 bits (= 1 byte)は 2の8乗ですから、0から255までの256通りを表すことができます。通常上4桁と下4桁に対して、16種類の記号 (0, 1, 2, 3, 4, 5, 6, 7, 7, 9, A, B, C, D, E, F : このようにしてあらわすことを16進法といいます)を割り当て、二けたの16進数で表記します。つまりたとえば
0000 0000 = 0x00 0001 0001 = 0x11 0010 0011 = 0x23 1000 1010 = 0x8A 1110 1111 = 0xEF 1111 1111 = 0xFF
というふうになります。頭に16進数表記であることを明記するために、0xというものを付けるのです。ちなみに上の数は通常我々が日常生活で用いている10進数で表現すれば、それぞれ、0, 17, 35, 138, 239, 255ということになります。つまり16進数を10進数に変換するためには次の計算をすれば良いのです。0x8Aを例にとれば・・・
8 x 16 + A(=10) = 128 + 10 = 138
ということになります。さて JPEGにおいては、16進数0xFFつまり1が8個連続することは特別の意味を持ちます。これは JPEG Tagの開始マーカーとして用いられるのです。このJPEG Tag開始マーカーに引き続いて0x00以外の数が続けば、その二つのセット、例えば 0xFF 0xD4などですが、これが何らかの意味を持つものとして扱われます。
さてここで疑問が生じます。ビット列は自然界の画像に応じて無限の組み合わせがあるので、たまたま0xFFとなることは256分の1の確率であり得る筈だ、だとすれば、どうやってそれが JPEG Tagなのかそうでないのかを見分けることができるのか? 僕はこの疑問に対してどうしても自分で答えることができませんでした。これに対して明確な回答を下さったのが、高村先生でした。
分かってしまえば簡単なことでした。JPEG Tagとして 0xFF 0x00という組み合わせをはじめから存在しなくしているのです。そして、このシークエンスがあれば、それ 0xFF 0x00 == 0xFF であるとみなすようになっているのです。これにより偶然おこるビット列 1の連続 8 bitsをきちんと情報伝達できるようにしているのです。何と賢い知恵なのでしょうか? 僕はこれを知って驚愕しました。
積年の謎が溶けかかりつつあります それは Canonical Huffman Code
2012年8月9日
自分の尊厳というか、誇りをかけて CないしC++を用いて、DICOM XA viewerを自分が死ぬまでに作成したいのです。何回も何回も挑戦しては、挫折の連続でした。
その挫折の原因は分かっているのです、どうしてもそこで使用されている Huffman Codeの decodingアルゴリズムを理解できないのです。
DICOM XAは要するにパラパラ漫画です。一枚の漫画は、JPEG Losslessで格納されているのです。JPEG Losslessという規格はもう何十年も昔に制定された国際規格であり、その規格書も読みました。そこでは、HUFFTABという領域に、Huffman Codeによる圧縮をdecodeするためのキーが書かれているのです。そこまでは掴みました。
しかし、どんなアルゴリズムの解説書を読んでも、ハフマン圧縮されたデータをデコードするためには、ハフマン木のデータが必要としか書いていません。ところが、このHUFFTABにはそんな木構造のデータは無く、表形式のデータしか無いのです。
その謎が、急に溶け始めました。まず、以前購入して難しくて読めなかった、もう廃刊となっている書籍 オーム社刊行の「映像情報符号化」という本です。
昨日この本を読んでいて、あっと思いました。そこには、ハフマン圧縮を行って実際に画像情報を圧縮するためには、いちいちハフマン木を作成しては効率が悪いので、テーブル参照法を用いると書いてありました。どうやらこれが求める回答のようでした。どうしてこんな大切なこと、他のアルゴリズムの数ある書籍には一言も記載が無いのでしょうか。
そして、本日届いた英語の書籍 "Managing Gigabytes" という本をチラチラ見ていたら、ついに見つけました。そのアルゴリズムを Canonical Huffman Codes と呼ぶらしいのです。あー 時間を相当そうですね、かれこれ4年間無駄にしました。最初にこれを知っていれば・・・
もっとも、JPEG Losslessなんて今時デジカメにも使用しないし、 DICOM XAでしか残っていない過去の遺物なので、それに用いる Canonical Huffman Codesなんてものも、世間から忘れ去られているのでしょうね。
ついについに近づいた
2012年8月13日
ここ数年がかりの自分のプロジェクト 言わずと知れた DICOM XA Viewerの作成です。その前提として、XA fileの中のDHT (Define Huffman Table)の解析が必要です。それに悩み、この難解なテーブルにどれだけの時間を注いできたことでしょう?
もちろん分からないのは僕が馬鹿だからなのです。でも、馬鹿といっても、そんなにひどい馬鹿ではないのです。この問題に悩んでいる人は世の中たくさんいる筈なのです。そして、ついに同じ悩みで苦しみ、そして万民のためにその秘密を解き明かしているページにヒットしたのです。これまで発見できなかった筈です、何故ならば比較的新しいページだからです。しかも、日本語でなく英語のページです。いやいやここで糠喜びは禁物です。もっと読み解き、理解する必要があります。しかし、ついについに近づいてきた、そんな予感がします。
JPEG DC成分のハフマン圧縮
2012年8月14日
再び挑み、ようやく目の前が開けてきました。今 3:30AMです。
そもそもの間違いは、JPEG losslessのDC成分に関するハフマン符号化圧縮についての大きな誤解でした。アルゴリズムの書籍などで紹介されているハフマン符号化では、ハフマン木を用いて符号化します。これによって、効率的に一意瞬時符号化・復号化が可能となるビット列を得ることができます。しかし、これらの書籍で紹介されているものは、その符号に対応するデータが1:1で対応付けられているのです。従って、最終的にはハフマン符号と対応データの対応付けの表が出来上がることになります。
しかし、JPEG Lossless DCではこれをしないのです。そこでのデータ格納形式は、ハフマン符号が表しているものは、データではないのです。データでなく、データを表現するビット数なのです。JPEG規格書では、この「データを表すビット数」のことを、「カテゴリー」と呼んでいます。日本語訳では、「分類」と訳されています。
これは一体何を表すのでしょうか? よく、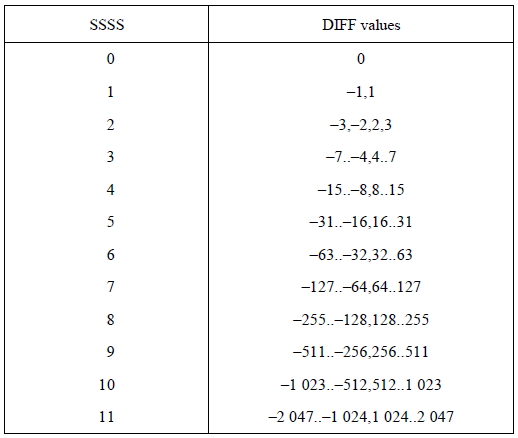 が出てきます。これを理解できませんでした。しかし、ついに本日理解しました。このビット数、つまりカテゴリーで表されるビット数のデータをビット・ストリームから取り出すのです。例えば
が出てきます。これを理解できませんでした。しかし、ついに本日理解しました。このビット数、つまりカテゴリーで表されるビット数のデータをビット・ストリームから取り出すのです。例えば
カテゴリ3に属するハフマン符号が "10" だとします そうすると次のビット列は
10110111110100
はどうなるでしょぅか?
これは 1010111110100 という風に判断されます。
つまり、赤字部分がハフマン符号であり、この部分がカテゴリ3に属するものと判断されます。従って、引き続く 3 bitsつまり青字部分がデータということになります。
101を二進数と考えられば、その値は 2x2x1 + 2x0 + 1 = 5ということになり、結果的に10101の 5 bitsで5という数字を表すことができました。もともと5という数字は 通常 8 bitsで表現されますので、この操作によって、 8 -> 5 というように 3 bits節約されたことになります。つまり、(8-5)/8 = 37.5%の圧縮率が達成されたことになります。
ここで、ピクセルのビット数、つまりレベルを8 bitsとします。これは通常用いられているもので、そもそも人間の眼が識別できる濃度差の限界とも言えるものです。もちろん、DICOM XAでも 8 bitsの濃度差しか使用していません。濃度差が 8 bitsということは、0から255までの値が当てはまります。
さっきの方法で圧縮しようとしても、例えば255というデータを表すためには 8 bits必要ですから、8 bitsのデータビットの前に、8 という数字を表すハフマン符号がつけたされることになります。そうすると、今度は逆に余計なビットが付加されることになり、圧縮どころかデータ量の拡大が起こってしまいます。しかしながら、実際の画像ではここで一工夫することにより、データがゼロの周囲に収束するようにしています。それは、ピクセル毎の差分値を用いるのです。自然画像では、濃淡はほとんどの場合滑らかに変化します。ということは、差分を取れば祖値は小さい、ということになります。JPEG輝度DC成分では自然画像のこの性質をうまく利用します。
実際にJPEG 輝度DC成分では、ここでのデータは、隣のピクセルとの差分値を当てることになっていますので、その大部分は一桁の値に集積することになります。さらに、工夫してあり、差分は、左右に隣のピクセルと行うのではなく、ジグザグに隣り合うピクセルとの間で差分を取るのです。JPEGではDC成分に関しては、左隣のピクセルとの差分をとりますが、ジグザグ走査は行いません。ジグザグ走査はAC成分についてのみ行われますので、JPEG Losslessにおいては使われません。
ここまで理解すれば、いかにアルゴリズム本の「ハフマン符号化」とは異なるかが分かります。そして、この違いが JPEGに対する理解を妨げているのです。そもそも何故、このようなややこしいことをしているのか? これは実際にもっと理解を進め、プログラムを書いてテストしなければなりませんが、現段階で言える僕の推測は・・・
JPEG規格制定当時、コンピューターで表される画像のサイズは比較的小さく、せいぜい1,024 x 1,024ぐらいしか無かった。従って、8 bitsの濃度を表す1:1のハフマン符号:データ の対応付け表を画像データの中に持てば、そのハフマン符号表部分が冗長なデータとしてサイズが巨大になってしまった。
結果的に、上で述べた方法、つまり、データとの直接変換表は持たずに、画像データそのものの中に埋め込んだ
このように理解しています。
bit入力 using C++
2012年8月15日
#define __READBITSTREAM_H_
#include <memory.h>
typedef unsigned char BYTE;
typedef unsigned int WORD;
class CReadBitStream
{
private:
protected:
BYTE *mbpRead; // 読み出しアドレス
BYTE *mbpEndOfBuf; // Bufferの終了アドレス
BYTE mMask; // bit maskであると同時に現在の読み出しビット位置 (MSB = 7, LSB = 0)
bool mReadable; // 1: 読み出し可、 0: 読み出し不可
void IncBuf(void); // 読み出しアドレスのインクリメントとアクセス違反のチェック
public:
CReadBitStream(void);
CReadBitStream(BYTE *bpBuf, int size); // 唯一のconstructor
virtual ~CReadBitStream(void);
BYTE GetByte(void); // 1 byte読み出し
WORD GetWord(void); // 1 word読み出し
void CopyBytes(BYTE* bpDest, int n); // n bytes読みだしてbpDestのアドレス以降にコピーする
void SkipByte(int n); // n bytes読み飛ばし
int GetBit(void); // 1 bit読みだして返す
int GetBits(int numOfBits); // numOfBits数のビットを読みだして返す
BYTE* GetNextAddress(void); // 次の読み出しアドレスを戻す
int ResetBuffer(BYTE* bpBuf, int size); // bufferを変更する
};
#endif __READBITSTREAM_H_
以前といっても、2010年12月に書いたプログラム探してきました。ビットストリームを扱うために、ファイルから読む込みためのクラスです。
JPEG DHTの解析
2012年8月16日
実際のDICOM XAより取り出したDHT (Define Huffman Table)セグメントを記載しますもちろん、16進数表記であり、1 byteづつ区切っています
FF C4 00 19 00 01 01 01 01 01 01 00 00 00 00 00 00 00 00 00 00 01 00 02 03 04 05
これではその中の意味ある分類ごとに改行しました
FF C4 00 19 00 01 01 01 01 01 01 00 00 00 00 00 00 00 00 00 00 01 00 02 03 04 05
さらに色づけしましょう
FF C4 00 19 00 01 01 01 01 01 01 00 00 00 00 00 00 00 00 00 00 01 00 02 03 04 05
ファイルのバイト列をサーチして、0xFFを探します。0xFFがあれば、その次が0x00であれば、それは0xFFというデータと見なされますが、0x00以外であれば、JPEGのタグと見なされます。 そして、FF C4というバイト列は、それがDHTの開始タグと見なされます。
次の、2 bytesつまり、ここでは00 19ですが、このバイト以降、何バイトがDHTであるかを示します。ここでは 0x0019ですので、16 + 9 = 25 bytesがDHTということになります。これで、01 00 02 03 04 05の最後の05までがDHTということが判明します。
次の 1 byteここでは、00ですが、これにより、このDHTはJPEGの中のDC成分(直流成分)を示し、ハフマンテーブル番号0ということが分かります。特に00というのは、輝度のDC成分という意味になります。まさしく、DICOM XAで用いているのは、輝度のDC成分のみなのです。皆も容易に分かるように、シネ画像は、白黒grey scale画像です。つまり、輝度情報しか持っておらず、DC成分ということは、二次元DCT (Discrete Cosine Transfer: 離散コサイン変換)による画像圧縮がされておらず、エントロピー圧縮しかされていない、つまり圧縮によって画像の情報が失われない lossless圧縮がされている、ということを意味しています。
さて、これからが問題です。
次の16 bytes固定、つまりここでは01 01 01 01 01 01 00 00 00 00 00 00 00 00 00 00ですが、この部分は、この部分の最初から、1bitのハフマン符号が1個、2 bitsのハフマン符号が1個、 3 bitsのハフマン符号が一個 ・・・・ということを表しています。
ということは、このファィルで使われているJPEG圧縮は、以下のハフマン符号を使っている、ということになります
はいここまで良いですね。
次のバイト列ですが、ここには、先の01 01 01 01 01 01 00 00 00 00 00 00 00 00 00 00部分の合計値個のバイト列が来ます。そして、意味するところは、それぞれのハフマン符号に続いて何ビットがデータ(その符号の意味)を表しているか? それを示します。
ここでは 01 00 02 03 04 05でしたので、 1 bitハフマン符号に続いては 1 bitがデータ、2 bitsのハフマン符号に続いては 0 bitがデータ、3 bitsハフマン符号に続いては、2 bitsがデータ、4 bitsハフマン符号に続いては、3 bitsがデータ、5 bitsハフマン符号に続いては4 bitsがデータ、6 bitsハフマン符号に続いては5 bitsがデータ ということを示しています。
ということは何を意味するのでしょうか? ここから先も理解するのは大変ですよっ
例えば ファイルの頭から読んで、ビット列を得ます。たとえばビット列 1110010011011011があったとします、これはどんな数字の列を表すでしょうか? 頭から順に 1 bitずつ取り出して、先のハフマン符号表と照らし合わせます。そうするとまず
1110 010011011011という風に、最初の4 bitsがヒットします。4 bitsハフマン符号に引き続く 3 bitsがデータでしたので、データ部分は次の緑部分
1110 010 011011011ということになります。このビット列 010を十進数であらわせば、0 x 4 + 0 x 2 + 0 = +2ということになります。従って、ここまでの最初の4 + 3 = 7 bitsで +2を表しました。
次いで、011011011の解析に移ります。再び先のハフマン符号表と照らし合わせますと、0 11011011というように1 bitハフマン符号にヒットしました。この場合、次の1 bitがデータということですから、1 1011011ということで、データは 1ということになります。当然この値は +1ですので、ここまでで十進法表記で、+2, +1と解読されました。
次の1011011部分の解読に移ります。再び先頭ビットからハフマン符号表をサーチします。そうすると、10 11011と2 bitsのビット列10でヒットしました 2 bitsのハフマン符号に引き続く0 bitがデータでしたね。うん? 0 bit? 何じゃそれは? つまり、この部分で 0というデータとなりました。つまりここまでで+2, +1, 0まで解読されましたね。さあ頑張りましょう 残るは11011でした。
これもハフマン符号表でサーチしましょう。そうすると、110 11というように110がヒットしましした。つまり3 bitsのハフマン符号です。この場合、続く2 bitsがデータ、ということになりますので、11つまり、2 + 1 = +3がデータということになります。こうして、数字列 +2, +1, 0, +3というようにこのビット列は解読されました。
ちなみに、それぞれの数字を非圧縮の状態つまり1 byte = 8 bitsで表すとすると8 x 4 = 32 bitsが必要です。しかしながら、我々が用いたデータ列1110010011011011は何と 16 bitsしかありません。従ってこの例では、(32 - 16)/32 = 50%という高い圧縮率が達成できた、ということになります。
難しいですね。僕の頭脳でもここまで理解するのに4年間かかりました。皆様方も頑張って下さいね。