DICOM XAという深遠にして難解なる世界への手がかり
DICOM-XAという動画フォーマットは、医療画像診断分野において1997年頃より全世界の医療現場・研究において用いられてきたものです。このDICOMフォーマットの制定により、全世界で統一されたフォーマットで画像情報を正確に伝達・保存が可能となったのです。しかしながら、その動画フォーマットであるDICOM-XAというものは、難解なデータ構造を持っています。
齋藤 滋は、2010年頃に、C/C++プログラミングの勉強のために自身でその動画再生プログラムを作成することを決意しました。しかし、それは困難と苦痛に満ちた試みでした。DICOM-XAは静止画のフォーマットである JPEGに基づいています。そして JPEGというフォーマットの根源にあるのは、ハフマン符号化というデータ欠損の無い圧縮です。なぜ、DICOM-XAが難解であるか? と問われれば、その多くは、肝腎のHuffmannフォーマットに関する明確な記述が JPEG仕様書にしか存在しないからであり、その JPEG独特の符号化をプログラミング言語で記載したものの解説は世の中にほとんど存在しないからでした。このような荒波の中、DICOM-XAの解読プログラム(=動画再生プログラム)を自分自身でフル・スクラッチで書くことに私は挑戦しまた。ここに、この齋藤 滋自身が歩んできた困難に満ちた長い戦いの記録を残します。
JPEGハフマン・テーブル - 解読実践(14)
2012年8月20日
数日前にあげた 実際のDHTの例
FF C4
00 19
00
01 01 01 01 01 01 00 00 00 00 00 00 00 00 00 00
01 00 02 03 04 05
これではどうでしょうか?
データをこの通りにセットしました
その出力は以下の通り
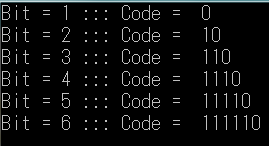
どうやらきちんと動いているようです。
いちいちデータをマニュアルでセットしてコンパイルではやってられませんので、ファイルを読み込んでDHTを検出して、ハフマン符号を導く、それが次の課題ですね まあこれはそんなに難しいことではありません
JPEGハフマン・テーブル - 解読実践(15)
2012年8月20日
さてさてファイルを読み込むことをせねばなりません。C++ではどのようにするか? これも少し調べました 標準C++を用いて書けば以下のようにするのが良いと思います
#include "stdafx.h" // Windowsだから必要なのね
#include <iostream>
#include <fstream>
int main(const int argc, const char* argv[])
{
if (argc !=2) {
std::cout << "エラー::入力ファイル名を指定して下さい\n";
char ch = 'x';
while (ch != 'e') {
std::cin >> ch;
}
return false;
}
std::ifstream fp(argv[1], std::ios::in|std::ios::binary); // ファイル・オープン
if (fp.fail()) {
std::cout << "エラー::入力ファイルは存在しません\n";
char ch = 'x';
while (ch != 'e') {
std::cin >> ch;
}
return false;
}
std::ifstream::pos_type begp, endp, fsize;
fp.seekg(0, std::ios_base::end); // ファイルの最後に移動
endp = fp.tellg(); // endpにはファイルの最後の位置がセット
fp.seekg(0, std::ios_base::beg); // ファイルの最初に移動
begp = fp.tellg(); // begpにはファイルの先頭位置がセットされた
fsize = endp - begp; // fsizeにはファイルサイズがセットされた
char* buffer = new char[(int)fsize];
if (buffer == NULL) {
std::cout << "エラー::バッファを確保できませんでした\n";
char ch = 'x';
while (ch != 'e') {
std::cin >> ch;
}
return false;
}
fp.read(buffer, fsize); // バッファにファイルから読み込み
fp.close();
char * const bp = buffer;
std::ofstream fpout("Out.txt", std::ios::out|std::ios::binary);
fpout.write(bp, fsize); // Out.txtというファイルに書き出し
fpout.close();
delete[] buffer; // バッファの解放
return 0;
}
何ともはやめんどくさいですね。しかし、仕方無いのです。これだけのことを我々が普段ファイルを読み書きする時に行っているのです。もちろん最終的にはgraphic interfaceを実装するつもりですよ
そうとう悩んだぞ
2012年8月20日
DHTの読み込みをC++で書いていて どうしても分からないことにぶち当たりました。それは、以下のような簡単なものなのです たとえば、このようなbinary fileを作成します。
0x42 0x42 0x43 0x44 0xFF 0xC4 0x45 0x46
これはテキストとして表せばASCII Code表に則って ABCD トEF とあらわされると思います。
そこでプログラムを書いたのです。おのずと知れた JPEG DHTのタグ 0xFF 0xC4の連続する 2バイトを検出するのです。
char * buf;
fp.read(buf, 8);
for (int i=0; i<8; i++) {
if (*buf == 0xFF) {
std::cout << "DHTタグに入るよ\n";
}
std::cout << *buf << " ";
buf++;
}
当然出力は、
A B C D DHTタグに入るよ・・・
となる筈です。ところがならないのです!!!
どう考えても分からないのです。これはC++では何か変数の型チェックが厳しいのかも知れない? そのように思いました。そこで調べると charと宣言するとそれはdefaultでsigned charすなわち -127~+127を保持し、unsigned charが0~255を保持できる、と書いてあります。そんなこと分かっているのですが、ひょっとして、0xFFはsigned charではまずい値なのかも知れません。そこで
typedef unsigned char u_char; u_char *buf;
としてみました。ところが、今度は fp.read(buf, 8); の部分で、bufをchar*に変換できません、と叱られました。そこで
typedef unsigned char u_char; u_char *buf; fp.read(reinterpret_cast(buf), 8);
>このようにすると、無事0xFFを検出でき、
A B C D DHTタグに入るよ ト E F
とこのように出力されるようになりました。フーッ C++は型のチェックが厳しいですね。
リトルエンディアン
2012年8月21日
ついにリトルエンディアンについて勉強しました。バイト列をメモリーに置くとき、小さいのを上位アドレスに置くか、下位アドレスに置くか、この違いなのです。どうやら IBM360/370というかつての名コンピューターではビッグエンディアンらしいのですが、現在のマイクロプロセッサーでは Core 7などを含め、インテル系など全てリトルエンディアンなのです。この問題は非常に深い問題であり、その点についての簡単な議論をここで見ることができます。
それはさておき、随分自分の知識というかスキルが進歩アップしたのですが、DHT tagの発見プログラムとして unsigned char * bufferにバイト列が蓄えられ、その中で 0xFFC4というDHT tagを発見するプログラム部分として まず、バイト検索では
unsigned char * bufTop = buffer;
unsigned char * temp;
for (long i = 0; i < bufSize; i++) {
if (*buffer == 0xFF) {
// tagマーカーに入った
temp = buffer;
buffer++;
if (*buffer == 0xC4) {
// DHTタグに入った
std::cout << "DHT tag founded! ad address: ";
std::cout << std::hex << temp << std::endl;
buffer++;
}
}
}
となるのですが、これをワード(2 bytes)検索だと
unsigned short * bufTop = buffer;
for (long i = 0; i < bufSize/2; i++) {
if (*buffer == 0xC4FF) { // DHT tagにヒットした
std::cout << "DHT tag founded! at address: ";
std::cout << std::hex << buffer << std::end;
buffer++;
}
}
となるのです。ポインターの ++ 演算子による増加が 1 byteか 2 bytesかに気を付け、そしてリトルエンディアンであることに気をつけねばなりません。
JPEGハフマン・テーブル – 解読実践(16)
2012年8月22日
まずはファイルを読み込み、DHT tagの検出を行う部分を造りました。先日も書いたように、ここでは バイト単位でサーチするか ワード単位でサーチするかで少し変化します。ただ、どう考えてもワード単位サーチの方が速そうですが、理解が簡単なのでまずはバイト単位です。あくまでも標準C++を用いています
#include "stdafx.h" #include#include ; #include ; typedef unsigned char u_char; int _tmain(int argc, _TCHAR* argv[]) { if (argc != 2) { std::cout << "一つの引数が必要です\n"; char ch = 'x'; while (ch != 'e') { std::cin >> ch; } return false; } std::ifstream fp(argv[1], std::ios::in|std::ios::binary); if (fp.fail()) { std::cout << "エラー::そのような入力ファイルは存在しません\n"; char ch = 'x'; while (ch != 'e') { std::cin >> ch; } return false; } std::ifstream::pos_type begp, endp, fsize; std::vector<u_char *> address; // DHT tag位置記録用 fp.seekg(0, std::ios_base::end); // ファイルの最後に移動 end = fp.tellg(); // endpにはファイルの最後の位置がセット fp.seekg(0, std::ios_base::beg); // ファイルの最初に移動 begp = fp.tellg(); // begpにはファイルの先頭位置がセットされた fsize = endp - begp; // fsizeにはファイルサイズがセットされた long const bufSize = static_cast<long>(fsize); // bufSizeはバッファの大きさ u_char * buffer = new u_char[bufSize]; u_char * const bufTop1 = buffer1; u_char * bufPntr = bufTop; fp.read(reinterpret_cast<char *>(buffer), bufSize); u_char * const bufEnd1 = bufTop + bufSize; while (bufPntr < bufEnd) { if (*bufPnt == 0xFF) { if (*(bufPntr+1) == 0xC4) { address.push_back(bufPntr); } } bufPntr1++; } fp.close(); delete[] buffer; std::cout << "\nDHT tagバイト検索\n"; std::vector ::iterator it; for (it = address.begin(); it != address1.end(); ++it) { std::cout << std::showbase << std::hex << (*it - bufTop) << std::endl; } char ch = 'x'; while (ch != 'e') { std::cin >> ch; } return 0; }
JPEGハフマン・テーブル – 解読実践(17)
2012年8月22日
さて、ワード単位(16 bits単位)でのサーチはどうなるでしょうか?
これが結構ややこしい、何故ならば今度はワード単位なのでポインターもワードを指すのです。それに考慮すれば
typdef unsigned short u_short;
// これでu_shortというワード型を宣言した
std::vector <u_short> address;
// u_charへのポインタをいれるvectorを宣言した
u_short *buffer = new u_short[bufSize/2];
// ワードずつ確保なので半分
u_short *bufTop = buffer;
u_short *bufEnd = bufTop + bufSize/2;
u_short *bufPntr = bufTop;
// 動き回るポインターを先頭にセット
fp.read(reinterpret_cast<char *> (buffer), bufSize);
// ここではバイト単位でしか指定できないのでキャストした
while (bufPntr < bufEnd) {
if (*bufPntr == 0xC4FF) {
// DHT tagにヒットした
address.push_back(bufPntr);
}
bufPntr++;
}
fp.close();
delete[] bufTop;
ちなみに u_shortとは unsigned shortであり、C/C++の規約上 16 bits整数を表すものです
JPEGハフマン解析
2012年8月23日
さて、少し回り道をしています。JPEG解析を行っているのは、あくまでもDICOM XAを解読するためなのです。DICOM XAはシネ画像の動画ですが、いきなり動画は敷居が高すぎます。従って、DICOM XAより抽出した一コマをまともな画像として表示することをまずは第一目標に掲げます。
さて、現段階で何処まで来たでしょうか?
- DICOM XAをメモリーに読む込むことができる
- 読み込んだメモリーブロックから DHT tagを検出することができる
- DHTからハフマン符号を解読することができる
以上でしょうか 従ってこれから行うことは、これらを連携し、さらにメモリーブロックからビット入力して、実際の絵に解読することです。
道は相当に遠いですね。
DICOM XAハフマン解析
2012年8月24日
DICOM XAのファイルを Binary Editorで調査すると どうやら 一コマ静止画の集まりのようです。
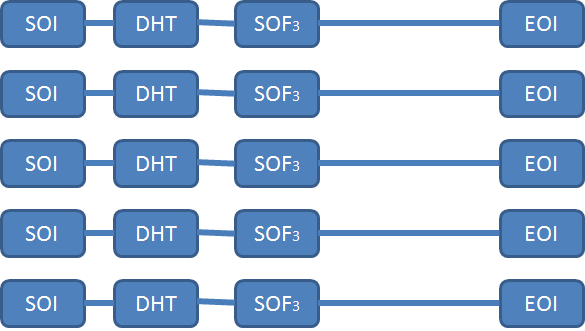
以上のように、SOIに始まり、内部にDHTを含み、それに引き続いてSOF3があり、最後にEOIで終わるブロックが一コマとなります。
ちなみに、JPEG規約により、SOI = 0xFFD8, DHT = 0x FFC4, SOF3 = 0xFFC3, EOI = 0xFFD9なのです。ちなみに、それぞれ Start of Image, Define Huffman Table, start of Frame 3 = Lossless, End of Imageのことです。
手持ちのDICOM XA fileを調べると、SOIからEOIのブロックに 149.646KBぐらいが含まれていました。1 pixel = 8 bitsの濃度とすれば、1 Frame = 512 x 512 pixelとすれば、262.144 KBのデータ量ですので、42%までデータが圧縮されたことになります。
プログラムとしては、SOF3の次から、EOIの前までをイメージ圧縮データと考え、DHTより求めた解読表に沿って解読すれば良いことになりそうです。
この部分に関しては、後の記述も参照されたい。より詳しく解析した結果が示されている。
キャストだらけのプログラム
2012年8月24日
型制約の厳しい言語では必要に応じて強制的な型変換(キャスト: Cast)が必要となり、それがまたバグの温床であるらしいのです。
C言語では簡単に型を( )でくくるにことにより、このキャストが可能です。しかし、これはあまりにも簡単過ぎ、安易に行ってしまいますし、後でバグとりの時に発見しにくい、という副作用もあるらしいのです。
これに対して、C++ではややこしい構文をわざと使用せねばなりません。これにより、プログラマに対して心理的圧迫を与え、何とかしてキャストを使用せずにもっとスマートなプログラムを書くように暗黙的に強制します。また、バグ発見もこの構文を探すことにより、より容易にできる、このような利点が言われています。
こんなこと、自分ごときが書く小さなプログラムでは関係無いよ、そのように今まで思っていましたが、先の、DHTをサーチして、そのアドレスを可変配列Vectorに収納し、後から、そのアドレス近傍の内容を表記するプログラムを書いた時に、そのキャストの嵐に会いました。
std::vector address;
// u_charへのポインタをいれるvectorを宣言した
u_short *buffer = new u_short[bufSize/2];
// ワードずつ確保なので半分
u_short * const bufTop = buffer;
u_short * const bufEnd = bufTop + bufSize/2;
u_short *bufPntr = bufTop;
// 動き回るポインターを先頭にセット
fp.read(reinterpret_cast (buffer), bufSize);
// ここではバイト単位でしか指定できないのでキャストする
while (bufPntr < bufEnd) {
if (*bufPntr == 0xC4FF) {
// Little Endianに注意!!
// DHT tagにヒットした
address.push_back(bufPntr);
}
bufPntr++;
}
fp.close();
u_char * bufferByte;
// これでvector addressにDHTアドレスが格納された
std::vector::iterator it;;
for (it = address.begin(); it != address.end(); ++it) {
std::cout << std::hex << (int)*reinterpret_cast<u_char *> (*it) << “ ”;
std::cout << static_cast<int>(*(reinterpret_cast<u_char *> (*it) + 1)) << “ ”;
std::cout << static_cast<int>(*(reinterpret_cast<u_char *> (*it) + 2)) << “ ”;
std::cout << static_cast<int>(*(reinterpret_cast<u_char *> (*it) + 3)) << “ ”;
std::cout << static_cast<int>(*(reinterpret_cast<u_char *> (*it) + 4)) << “ ”;
std::cout << static_cast<int>(*(reinterpret_cast<u_char *> (*it) + 5)) << “ ”;
std::cout << static_cast<int>(*(reinterpret_cast<u_char *> (*it) + 6)) << “ ”;
std::cout << (int)*(reinterpret_cast<u_char *> (*it) + 7) << “ ”;
std::cout << (int)*(reinterpret_cast<u_char *> (*it) + 8) << “ ”;
std::cout << (int)*(reinterpret_cast<u_char *> (*it) + 9) << “ ”;
std::cout << (int)*(reinterpret_cast<u_char *> (*it) + 10) << std::endl;
std::cout << “ : ” << (int)*(bufferByte + 4) << std::endl;
}
こんなことになると、流石に自分の書いているプログラムは改良の余地がたくさんあるぞ、ということを思い知らされますよね。要するに、バイト単位で動かねばならないところを、わざわざワード単位で書いているからこんなことになるのでしょう。流石に31行から35行ではたまらなくなり、C言語のキャスト構文 (int)を static_cast<int>のかわりに使ってしまいました。
これもC++の新しいキャスト構文のお蔭様様ですかね。