DICOM XAという深遠にして難解なる世界への手がかり
DICOM-XAという動画フォーマットは、医療画像診断分野において1997年頃より全世界の医療現場・研究において用いられてきたものです。このDICOMフォーマットの制定により、全世界で統一されたフォーマットで画像情報を正確に伝達・保存が可能となったのです。しかしながら、その動画フォーマットであるDICOM-XAというものは、難解なデータ構造を持っています。
齋藤 滋は、2010年頃に、C/C++プログラミングの勉強のために自身でその動画再生プログラムを作成することを決意しました。しかし、それは困難と苦痛に満ちた試みでした。DICOM-XAは静止画のフォーマットである JPEGに基づいています。そして JPEGというフォーマットの根源にあるのは、ハフマン符号化というデータ欠損の無い圧縮です。なぜ、DICOM-XAが難解であるか? と問われれば、その多くは、肝腎のHuffmannフォーマットに関する明確な記述が JPEG仕様書にしか存在しないからであり、その JPEG独特の符号化をプログラミング言語で記載したものの解説は世の中にほとんど存在しないからでした。このような荒波の中、DICOM-XAの解読プログラム(=動画再生プログラム)を自分自身でフル・スクラッチで書くことに私は挑戦しまた。ここに、この齋藤 滋自身が歩んできた困難に満ちた長い戦いの記録を残します。
ビットストリーム (Bit Stream)入力クラス
2012年8月25日
以前(2008年頃)書いたプログラムを引っ張り出しました。そしてバグを発見したので、少し書きなおしました。もうバグは無いと思いますが・・・
// // ReadBitStream Class //// unsigned char * bpBufに sizeバイト置かれたメモリーブロックから //// bit単位で値を取り出すクラス //// エラーがあれば、throwするので、読みだす方は try ~~ catch すべき //// modified on August 25th, 2012 //// by Shigeru SAITO, MD, FACC, FSCAI, FJCC //// originally created by Shigeru SAITO in 2008 // #ifndef __READBITSTREAM_H_ #define __READBITSTREAM_H_ #includetypedef unsigned char BYTE; typedef unsigned short WORD; class CReadBitStream { private: protected: BYTE *mbpRead; // 読み出しアドレス BYTE *mbpEndOfBuf; // Bufferの終了アドレス BYTE mMask; // bit maskであると同時に現在の読み出しビット位置 (MSB = 7, LSB = 0) bool mReadable; // 1: 読み出し可、 0: 読み出し不可 void IncBuf(void); // 読み出しアドレスのインクリメントとアクセス違反のチェック public: CReadBitStream(void); CReadBitStream(BYTE *bpBuf, int size); // 唯一のconstructor virtual ~CReadBitStream(void); BYTE GetBYTE(void); // 1 BYTE読み出し WORD GetWORD(void); // 1 WORD読み出し void CopyBYTEs(BYTE* bpDest, int n); // n BYTEs読みだしてbpDestのアドレス以降にコピーする void SkipBYTE(int n); // n BYTEs読み飛ばし int GetBit(void); // 1 bit読みだして返す int GetBits(int numOfBits); // numOfBits数のビットを読みだして返す BYTE* GetNextAddress(void); // 次の読み出しアドレスを戻す int ResetBuffer(BYTE* bpBuf, int size); // bufferを変更する }; #endif __READBITSTREAM_H_
上がheader部分です、そして.cppの方は以下です
#include “ReadBitStream.h”
CReadBitStream::CReadBitStream(void)
:mbpRead(0), mbpEndOfBuf(0), mMask(0), mReadable(false) {}
CReadBitStream::CReadBitStream(BYTE *bpBuf, int size) {
mbpRead = bpBuf; // 読み出しアドレスをbufferの先頭にセット
mbpEndOfBuf = mbpRead + size; // bufferの最終アドレスをセット
// 状態変数の初期化
mMask = static_cast<BYTE>(0x80); // setMSB
mReadable = true; // アクセスエラー無し
}
int CReadBitStream::ResetBuffer(BYTE *bpBuf, int size) {
mbpRead = bpBuf;
mbpEndOfBuf = mbpRead + size;
if ((bpBuf == 0)||(size == 0)) {
mReadable = false;
return -1;
}
mMask = static_cast<BYTE>(0x80);
mReadable = true;
return 0;
}
CReadBitStream::~CReadBitStream(void) {
mbpRead = 0;
mbpEndOfBuf = 0;
}
BYTE CReadBitStream::GetBYTE(void) { // 1 BYTE読み出し
if (mReadable) {
if (!(mMask > 0x80)) { // BYTE途中は不可
IncBuf(); // 次のBYTEに進める
mMask = static_cast<BYTE>(0x80);
}
BYTE r = *mbpRead; // 実際に1 BYTE読みだす
IncBuf();
return r;
} else {
throw(“Error at GetBYTE”);
}
}
WORD CReadBitStream::GetWORD(void) { // 1 WORD読み出し
if (mReadable) {
if (!(mMask > 0x80)) { // BYTE途中は不可
IncBuf();
mMask = static_cast<BYTE>(0x80);
}
WORD r = (static_cast<WORD>(*mbpRead))<<8;
// 1 BYTE読み出しそれをWORDにcastしてから8bits左シフト
IncBuf();
r |= static_cast(*mbpRead);
// さらに1 BYTEを下のBYTEに付加する
IncBuf();
return r;
} else {
throw(“Error at GetWORD”);
}
}
void CReadBitStream::CopyBYTEs(BYTE* bpDest, int n) {
// n BYTEsをpbDestに一挙にコピーしてしまう
if (mReadable) {
if (!(mMask > 0x80)) { // BYTE途中は不可
IncBuf();
mMask = static_cast<BYTE>(0x80);
}
if (mbpRead + n > mbpEndOfBuf) {
throw(“Error at CopyBYTEs1″);
}
memcpy(bpDest, mbpRead, n);
if ((mbpRead += n) >= mbpEndOfBuf) mReadable = false;
// 次の読み出しは不可
return;
} else {
throw(“Error at CopyBYTEs2″);
}
}
void CReadBitStream::SkipBYTE(int n) { // n BYTEs読み飛ばす
if ((mbpRead + n) > mbpEndOfBuf) {
throw (“Error at SkipBYTE”);
}
if ((mbpRead += n) >= mbpEndOfBuf) mReadable = false;
// 次の読み出しは不可
mMask = static_cast<BYTE>(0x80);
return;
}
int CReadBitStream::GetBit(void) { // 1 bit読みだす
if (mReadable) {
int r;
r = (*mbpRead > mMask) ? 1:0;
mMask >>= 1;
if (mMask == 0x00) {
mMask = static_cast<BYTE>(0x80);
IncBuf();
}
return r;
} else {
throw(“Error at GetBit **”);
}
}
int CReadBitStream::GetBits(int numOfBits) {
// numOfBits読みだす (0 < n <= 16)
if ((numOfBits <= 0)||(numOfBits > 16)) {
throw(“Error at GetBits of numOfBits”);
}
if (!mReadable) throw(“Error at GetBits Initial”);
int r = 0;
while (numOfBits) {
if (mReadable) {
if (mMask == 0x00) {
mMask = static_cast<BYTE>(0x80);
IncBuf();
}
r <<= 1;
r |= ((*mbpRead > mMask) ? 1: 0);
mMask >>= 1;
numOfBits–-;
} else {
throw(“Error at GetBits”);
}
}
return r;
}
void CReadBitStream::IncBuf(void){
// buffer読み出しを1 BYTE進める
if (++mbpRead >= mbpEndOfBuf) mReadable = false;
// 次は読み出し不可にする
}
どうでしょうか? 自分で書いたテスト・プログラムでは大丈夫なようです。エラーがあれば、きちんとthrowされています。
またまたバカやっていた
2012年8月28日
今朝病院に出勤する自転車を漕ぎながらふと疑問が湧きました それは
JPEG Losless DC成分で用いるハフマン符号は、12 bitsの差分値まで対象としている それであれば、1 pixel = 8 bitsと固定していてはいけないのではないか?
というものでした。これまでは、DICOM XAではどうせ1 pixel = 8 bits固定と考えていたのですが、もちろそれは大多数の場合正しいのですが、本当に良いのでしょうか?
そこで再び DICOM規格書に戻ると、これはDICOM tabでbits allocatedなどで何ビットを一ピクセルに指定するか? それが指定されているのです。
そこで、DICOM tagを検索したのです。これもSterlingで行いましたが、無い! 無い! そんなタグ無い!でした。いやいやそんな訳無い、と思い、今度はVisualStudioでbinary openして調べて気が付きました。結局、little endianで並んでいるので、
0×00 0×28で検索してはヒットしません。
0×28 0×00で検索せねばならなかったのです。まったくバカしていましたね。
こんなの見つけました
2012年8月28日
DICOM Tagについてあれこれ調べている内にこんなページを見つけました。京都大学大学院の方ですね
http://www.kuhp.kyoto-u.ac.jp/~diag_rad/ここで、フリーのDICOM Viewerをダウンロードできます。残念ながら DICOM XAには対応していないようです。
疑問解消
2012年8月29日
昨日来、Binary Editorを用いて、実際のDICOM fileを解析してきました。そもそも今更これを行っているのは、先日出勤時の自転車で、「あれ? DICOM XAは 1 pixel -> 8 bitsと固定していいのかな?」という疑問からでした。
そうして見直してみると、0x0028 0x0001という Bits Allocatedという DICOM Tagがあるのです。しかし、ここで問題でした。Binary Editorで見てみても、このタグに続くバイト列は
0x28 0x00 0x00 0x01 0x55 0x53 0x02 0x00 0x08 0x00 0x28 0x00 0x01 0x01
という風になっているのです。ちなみに色分けすれば
0x28 0x00 0x00 0x01 0x55 0x53 0x02 0x00 0x08 0x00 0x28 0x00 0x01 0x01
となります。赤字はDICOM Tagです。次の0x55 0x53はアスキーで “US”となります。これは超音波の意味ではなく、unsigned shortの意味であり、C/C++で定義されているデータ型です。つまり16 bits WORDなのです。
そして、次の黄色の部分にそれ以降何バイトが値なのか? が記載され、ここでは2 bytesです。従って、その次の紫色が値となり、値 = 8が得られます。
最初のタグの意味は、Bits Allocatedなので、このデータ列の意味するところは、1ピクセルは、8 bitsで表現されますよ、という意味です。これで、このDICOM XA fileは、1 pixel -> 1 byteで画素が表現されていることになります。
遅々として、しかし着実に進展
2012年9月4日
DICOM XA Viewerの作成プロジェクト何処までいきましたかね?
もちちろん自分は一義的には Interventional Cardiologistであり、医師であり、プログラマではありませんので、なかなか進みません。そして、何よりも心の問題です。これまで、何年も目標として頑張ってきて、心の何処かに何時も、解けない難問として横たわっていたものが、どうやらもうすぐ解けそう、と思った時、「あー、これで目標が無くなるのか?」という恐れも湧いてきたのです。それが、前に進むのを妨げているのです。
とは言っても、本当に解けるのか? それは実現せねばわかりません。という訳でゆっくりとタラタラやっています。まずは、ファイル読み込みをメモリー中のバッファに展開するクラスを作成しました。といっても今までのクラスを一つにまとめただけですが・・・
このクラスでは、ファイルを読み込み、エラーがあれば、エラー送出クラスでエラーを送り、無ければメモリー中のバッファに展開し、ビット入出力のためのインターフェースを提供します。実装して、基礎的なテストを行い、作動することを確認しています。ヘッダ部分のみ掲載しましょう。
class CBitBuffer
{
protected:
BYTE *bufTop; // Bufferの開始アドレス
BYTE *bufEnd; // Bufferの終了アドレス
long bufSize; // Bufferのサイズ
BYTE *mbpRead; // 読み出しアドレス
BYTE mMask; // bit maskであると同時に現在の読み出しビット位置 (MSB = 7, LSB = 0)
bool mReadable; // 1: 読み出し可、 0: 読み出し不可
void IncBuf(void); // 読み出しアドレスのインクリメントとアクセス違反のチェック
public:
CBitBuffer(void);
CBitBuffer(const int argc, const char* argv); // ファイルを読み込んでbufferに収納
virtual ~CBitBuffer(void);
BYTE *getBufTop(void); // 内部bufferの先頭アドレス
long getFileSize(void); // 内部bufferの大きさ
BYTE *getBufEnd(void); // 内部bufferの最終アドレス
BYTE GetBYTE(void); // 1 BYTE読み出し
WORD GetWORD(void); // 1 WORD読み出し
void CopyBYTEs(BYTE *bpDest, int n); // n BYTEs読みだしてbpDestのアドレス以降にコピーする
void SkipBYTE(int n); // n BYTEs読み飛ばし
int GetBit(void); // 1 bit読みだして返す
int GetBits(int numOfBits); // numOfBits数のビットを読みだして返す
BYTE *GetNextAddress(void); // 次の読み出しアドレスを返す
};
そうなると再び登場 - 二進出力を可能とした ostreamクラス
2012年9月4日
そうなると、出力チェックのために 少し仕掛けが必要です。これも大分前に作成したプログラム部品です
#ifndef __OSTREAM_H_
#define __OSTREAM_H_
// 二進出力を可能とした ostream (Programmedd by Shigeru SAITO, MD on June 5th, 2009)
// modified by S. SAITO, MD on December 14th, 2010
// 使い方: このheader fileをインクルードし、名前空間ostを用いてcoutに出力する
// ost::ostream cout; とcoutを生成し、
// cout << value;
// のように使う、そして標準出力については std::cout << std::endl; のようにする
// 入力の型(BYTE, WORD, int)に応じて自動的に8桁、16桁で出力するがsetw()で出力桁数を変更できる
#include <iostream>
#include <iomanip>
#include <string>
typedef unsigned char BYTE;
typedef unsigned short WORD;
namespace ost {
enum e_manip {bin, hex, dec, endl};
class setw {
int width_;
setw() {} // 引数無しコンストラクタ禁止
public:
setw(int n);
int get_width(void) const;
};
class ostream {
private:
int width, bitWidth;
e_manip mManip;
bool mIsSetW;
void setWidth(int w);
void out(int n);
public:
ostream();
ostream & operator << (const setw & sw);
ostream & operator << (const e_manip em);
ostream & operator << (const BYTE n);
ostream & operator << (const WORD n);
ostream & operator << (const int n);
ostream & operator << (const char* s);
ostream & operator << (const std::string str);
};
}; // namespace ost
そして.cppです
#include "ostream.h"
#include "stdafx.h"
namespace ost {
setw::setw(int n): width_(n) {
if (width_ < 1) width_ = 1;
if (width_ > 16) width_ = 16;
}
int setw::get_width(void) const { return width_; }
void ostream::out(int n) {
int printWidth = 0;
mIsSetW ? (printWidth = width): (printWidth = bitWidth);
switch (mManip) {
case bin:
for (int i = printWidth; i > 0; --i) {
std::cout << (((n >> (i - 1)) & 0x001) ? '1': '0');
if ((i != 8) && ((i - 1)%4 == 0)) std::cout << " ";
}
break;
case hex:
std::cout << "0x" << std::hex << std::setw(printWidth) << std::setfill('0') << n;
std::cout << " ";
break;
case dec:
std::cout << std::dec << std::setw(printWidth) << std::setfill('0') << n;
break;
default:
break;
}
}
ostream::ostream(): width(1), bitWidth(8), mManip(bin), mIsSetW(false) {}
ostream& ostream::operator << (const setw & sw) {
width = sw.get_width();
mIsSetW = true;
return *this;
}
ostream& ostream::operator << (const e_manip em) {
if (em == endl) { std::cout << std::endl; } else { mManip = em; }
mIsSetW = false;
return *this;
}
ostream & ostream::operator << (const BYTE n) {
switch (mManip) {
case bin:
bitWidth = 8;
break;
case hex:
bitWidth = 2;
break;
case dec:
bitWidth = 3;
break;
}
out(static_cast(n));
mIsSetW = false;
return *this;
}
ostream & ostream::operator << (const WORD n) {
switch (mManip) {
case bin:
bitWidth = 16;
break;
case hex:
bitWidth = 4;
break;
case dec:
bitWidth = 5;
break;
}
out(static_cast(n));
mIsSetW = false;
return *this;
}
ostream & ostream::operator << (const int n) {
switch (mManip) {
case bin:
bitWidth = 16;
break;
case hex:
bitWidth = 4;
break;
case dec:
bitWidth = 5;
break;
}
out(n);
mIsSetW = false;
return *this;
}
ostream & ostream::operator << (const char* s) {
std::cout << s;
mIsSetW = false;
return *this;
}
ostream & ostream::operator << (const std::string str) {
std::cout << str;
mIsSetW = false;
return *this;
}
} // namespace ost
何と 2009年6月に作ったものなのですね。二進出力を可能とするクラスです。どうしてC++やCに二進出力が標準的に備わっていないのか不思議で仕方ありません。普段使わない八進出力なんて存在するのに・・・です。
やったね 今京都
2012年9月4日
京都に来るまでの間にプログラム進みました このような出力見て感激です
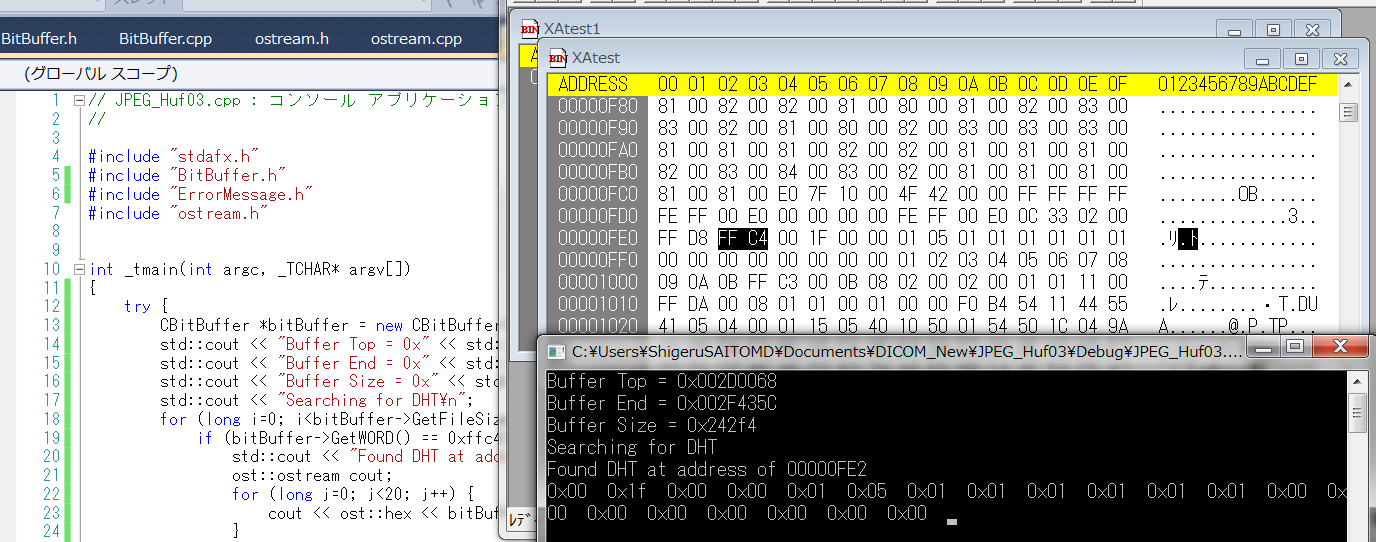
素晴らしいですね
少し洗練化
2012年9月5日
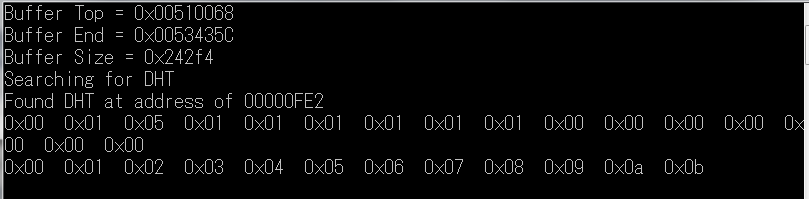
少しDHTの意味について思いだし、出力を少しだけ洗練しました。
ここまで来ました
2012年9月5日
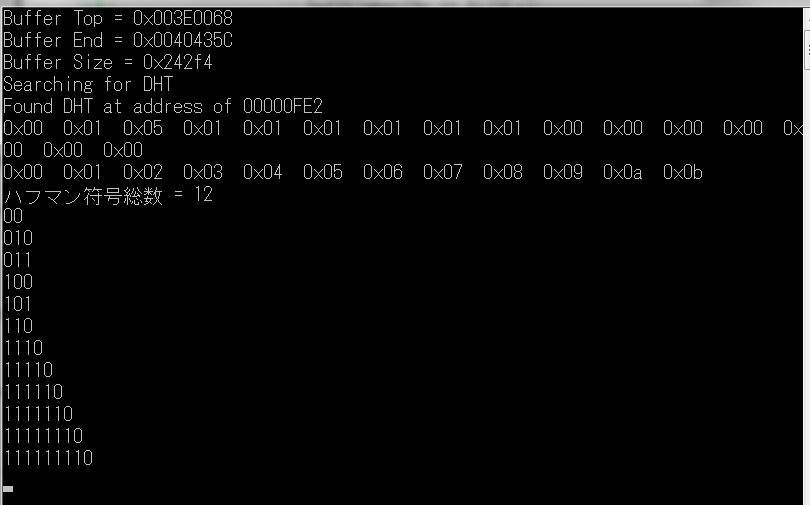
試行錯誤の末、やっとここまで来ました ファイルを読み込んでメモリー中のバッファに展開し、自動的にDHTを検出し、ハフマン符号を生成しています。
そしてついにハフマン符号表が完成です
2012年9月5日
そらに改良しました。ハフマン符号と、その値の組み合わせ、つまりハフマン符号表を完成させました。もちろん実際のDICOM Viewerにおいては、こんな表をいちいち見せません。これはあくまでもプログラムのチェック用にわざわざ出力させているのです。
実際のDICOM XA fileを読み込み、DHTを解読し、ハフマン符号とそれが示す値(この値は、続く何ビットが実際の値かを示しています{{ asset('docs-assets/DICOM-Figures/DICOM3.png') }}" width="801" height="560" alt="DICOM3" />
ハフマン符号表は完成したものの
2012年9月7日
一昨日ハフマン符号表解読プログラムが完成したものの、いくつかのDICOM XA fileを解読していたらこんな符号表に出くわしました
あれあれ?という感じです 何故ってビット長が何と値 16まであるのです。だって、DICOM XAの1 pixelは 8bitsの深度の筈です。実際のこのファイルのBits Allocatedなどを調べても8 bitsとしてしか記載は無いのです。だとすると、その値の差分も8 bits以内に収まらねばなりません。これってどういうこと? 何で 16 bitsあるの?
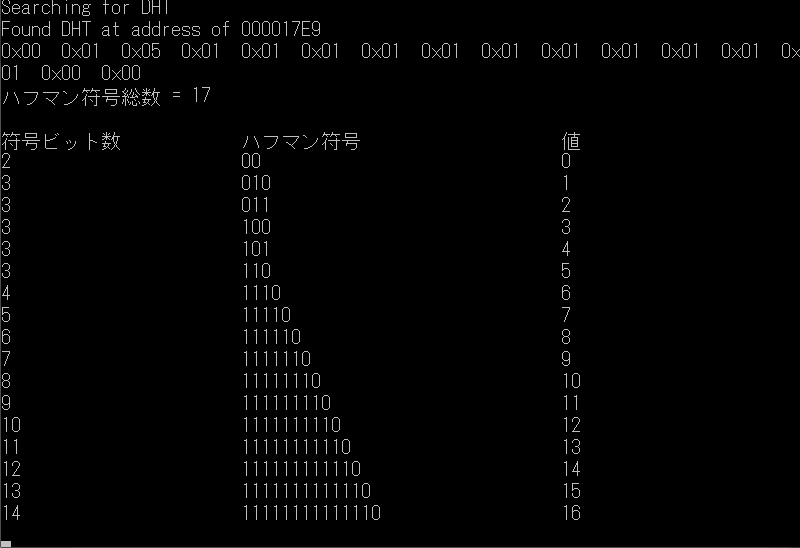
誰か御存知の方 ご指導頂けませんでしょうか? 大混乱しています。
DICOM viewer作製にあたって参照すべきページ
2012年9月9日
NEMA DICOM HomePage
一般社団法人 日本画像医療システム工業会
JPEG規格書
DICOM ToolKit - DCMKT
(X) MedCon
Radis DICOM Viewer
DICOM XA解析
2012年9月12日
さてさて疑問は尽きぬものの、ゆっくりとDICOM Viewerに向けて進んでいます。その過程で改めてC++について学びながらやっていますので、本当にゆっくりしか進みません。
今迄したことは
- ファイルをメモリーに読み込む
- ファイル内容をメモリー・バッファに展開する
- これらの過程で例外が発生すれば例外クラスを用いてキャッチする
- メモリー・バッファをスキャンして、何コマ(何フレーム)かを見出し、その過程でJPEG Tagを検出する
- メモリー・バッファからDHTを読み、ハフマン表を作成する
- フレームを指定してビット出力をメモリー・バッファに命じ、ハフマン表から解読する
- 解読結果をビットマップに転送する
実際のファィルを調べるとどうやらDHTはファイル毎に同一であり、両端マーカーはこのようになっていました

SOF3については、位置が一定ではないようです。そして、それぞれのタグの間には何か分からない意味の無いデータが何バイトか挟まっています。何れにしてもイメージ・データの両端はSOS (Start of Scan)とEOI (End of Image)のようです。